Improving on our json Lua module
By Mathias Westerdahl on Nov 18, 2022
We’ve had a long standing request to implement a json.encode() function in our json Lua module.
Previously, our users have had to resort to using a plugin, such as the excellent defold-cjson extension from our community.
We actually implemented the json.encode() in our 1.3.7 release, but it used a library that operates on a C-to-Lua level.
Our json.decode() implementation used a different library, and we wanted to consolidate the two functions, and at the same time look over our C++ sdk api dmJson.
Our decoder implementation was using jsmn.c, and while it certainly is small (440loc), it really is one of the slower json decoders you can pick out there. Also, I didn’t feel our own C++ dmJson::Parse() API was very great.
In fact it wasn’t much of an API at all, but rather just exposing the internal structures of the parsed content. It let the user parse the hierarchy themselves:
struct Node
{
/// Node type
Type m_Type;
/// Start index inclusive into document json-data
int m_Start;
/// End index exclusive into document json-data
int m_End;
/// Size. Only applicable for arrays and objects
int m_Size;
/// Sibling index
int m_Sibling;
};
struct Document
{
/// Array of nodes. First node is root
Node* m_Nodes;
/// Total number of nodes
int m_NodeCount;
/// Json-data (unescaped)
char* m_Json;
/// User-data
void* m_UserData;
};
This is not a great api. And what’s even worse, is that changing it would either break our own API, or force us to write an elaborate wrapper to present the data the same way.
While it’s rare, we realized we needed to break the api here.
What to look for?
Once we had decided that we needed to break the API, it allowed us to choose a C library that suited our needs. We should be able to write a new wrapped on top of it.
What do we look for when choosing a library?
While much can be said about the criteria, it will always be a compromise between various things:
- Performance
- Code size
- Easy of use
- Code dependencies
For performance, we generally choose C libraries, since they tend to be more to-the-point, and don’t involve too much of the modern C++ that easily goes out of scope. For good performance, it is also important that the number of allocations are under control.
Code size is very important for us, so we want to make sure keep the engine runtime as small as possible. And since this is a core functionality of the engine, we don’t want all users to pay for the added size.
Ease of use is perhaps a bit unclear, but it’s good if the api looks a bit similar to other libraries in terms of the api. That makes it a bit easier if you decide to switch out the backend library at a later date.
For code dependencies, it’s important that the library doesn’t force you to use other libraries that you don’t want to use. For instance, we don’t use STL for several reasons, and that’s one of the requirements for us when choosing a library. Also, make sure that the code dependencies you introduce actually work on all platforms you support. It is easy enough to miss, even if the dependency looks ok.
What alternatives are there?
The first step was to gather a small list of candidates. I started with github and looked through the top matches that seemed to fit the criteria closely enough.
The more libraries I collected, I added them to my small testsuite I wrote to keep track of the comparisons. Here’s a comparison of some libraries:
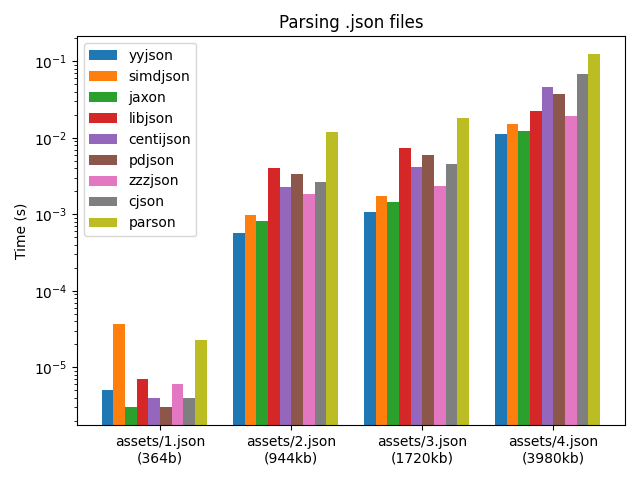
I did assume, a little bit naively, that there already existed some accepted best-practices C library that fit our criteria. Or at least a few cnadidates. But as I looked closer and closer, I felt more and more discouraged.
It was always a tradeoff that felt a little bit “too much” for me to accept. Either it was the parsing speed, or it was code size or the memory usage. To me it never felt ok that a library uses 130mb memory to parse a 4mb json file.
That’s when I started to look into the libraries that used the least amount of memory, the “sax” parsers.
Around the same time I also found another test suite that outlined a lot of the questions I had. Ultimately, the task grew harder.
On-the-fly Parsers
For XML, the term SAX parser is used when parsing a document on the fly, without explicitly returning a DOM structure. It is also called event-based-parsing.
The parsing generates events like OBJECT_BEGIN and OBJECT_END, and it is the caller’s responsibility to use the information.
You can generate a DOM hierarchy if you wish, but you don’t have to.
A big benefit of event driven parsers, is that they’re fast, and don’t need to allocate a lot of memory.
Why the C++ api?
At this point I realized that I had overestimed the use cases for the json parser.
In a nutshell, our users needed it to convert to and from C and Lua.
In the engine, we only used our dmJson api to do verification of an HTML5 callstack.
Then we stored the callstack blob as-is. We never actually used the json info itself.
Our users actually never needed a full C++ DOM api for the json structure. And if they do need it in the future, we/they could easily extend the engine by writing a native extension.
So, this led us to the conclusion that we would remove the old dmJson api altogether, and instead introduce improved functionality in our scripting api to convert to-and-from Lua and C.
json.decode(json_text)
local json_text = json.encode(data_table)
int dmScript::JsonToLua(lua_State* L, const char* json, size_t json_len);
int dmScript::LuaToJson(lua_State* L, char** json, size_t* json_len);
The actual library we chose in the end is lua-cjson.
These changes will land in the Defold 1.4.0 release.